This project came out of my participation in a Google-sponsored Kaggle competition to detect the relationships between pairs of objects in a picture.
Example:
 Expected Output:
Expected Output: man playing guitar
Goals
- Detect the bounding boxes for each object in an image (62 object classes)
- For each pairs of objects that could relationships we’re looking for (329 distinct ones), identify the relationship
- In addition to relationships, certain objects (such as table or chair) has attributes that must be identified as well (ex: chair is wooden)
Thoughts & approach
Looking at the goals, there will be an object detection (localization) task first followed by a classification task.
Deep learning tasks with images have the benefit of our visual intuition as well as biases that come with our perceptions. From the image above it’s easy to spot that a man can only hold a guitar in certain ways, so one feature I incorporate is the spatial relationship between the bounding box of the man and the bounding box of the guitar. However if I’ve trained the network too well to only spot a man standing with a guitar because I’ve never seen someone laying down with a guitar, then my network won’t generalize well.
In addition to spatial features, I’ll add an image classification network that only considers a cropped portion of the image as its input. This way the network can learn the shapes and patterns from scratch of how man and guitar goes together. The downside of this is that it takes a lot of data to get good results. If there’s a scarcity of data of any of the classes, this piece of the classification pipeline will not generalize well.
Another sanity check I can add is around the probable relationships given the linguistic names of the objects. For example, it’s likely that for man rides horse to be documented in a picture, but it’s very improbable for man holds horse to happen. The second might not even be in our list of possible relationships. Inspiration for this was from the Visual Relationship detection work of Lu, Cewu and Krishna, Ranjay and Bernstein, Michael and Fei-Fei, Li (article). In the paper, the author used a language module trained on common word associations to narrow down the relationship possibilities for an image.
Finally because the first three relationship classification tasks depend heavily on the precision of the individual object detection network, they are prone to fail when the object detection fails. To add another sanity check, I could train a separate “object” detection network around the 329 possible relationship classes. This requires a lot of training time, so I’ll save work until I’ve tried the other 3.
Both image classification and object detection relies on a convolution neural network (CNN) backbone that is able to break down an image across many dimensions and visual qualities such as lines, shapes, patterns, colors. I start with the resnet-50 backbone for both tasks.
The object detection task will rely only on the image as input and output bounding boxes around where the objects are in the image and what types of objects are there.
The classification task will rely on:
- A cropped area of the image in the shape of the union of two object bounding boxes from the object detection task
- The bounding boxes themselves
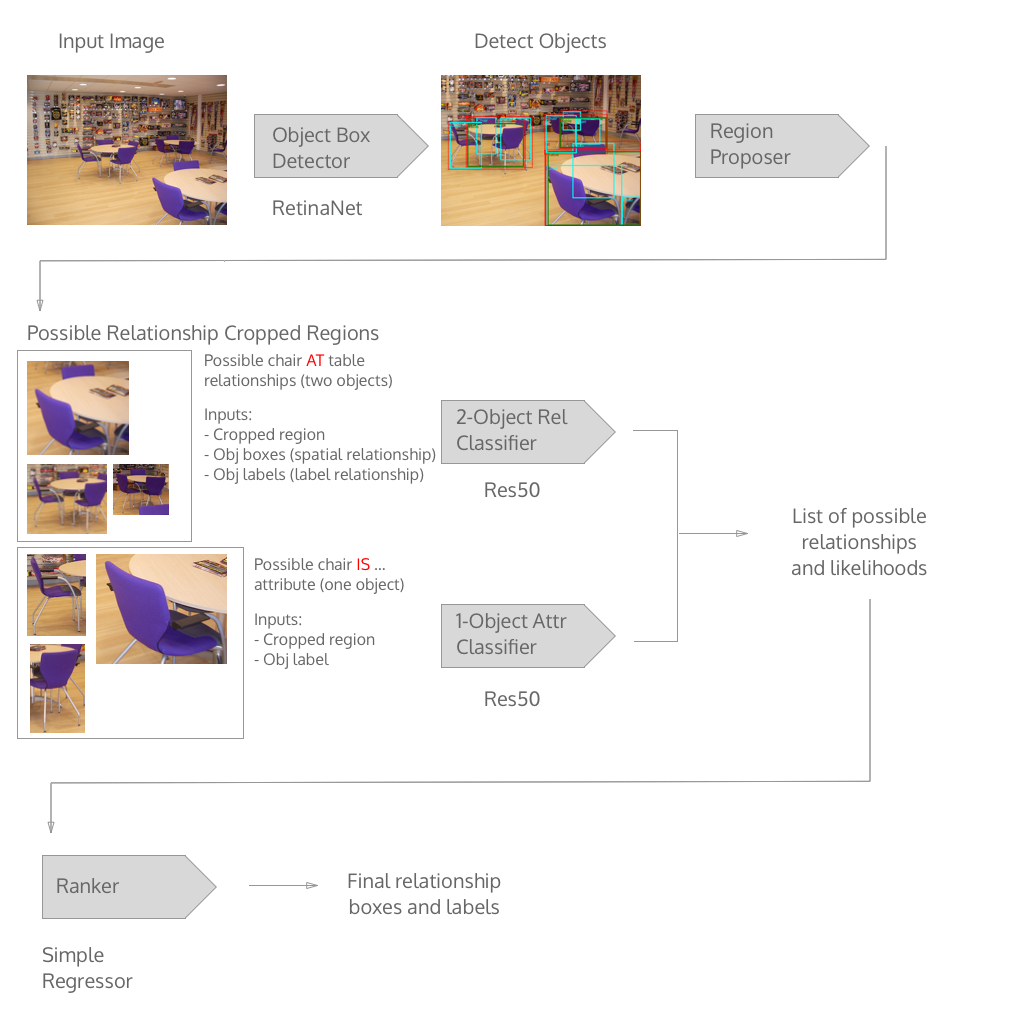
For the object detection task, there has been great work done on object detection from 2-step methods such as Faster RCNN to single pass methods such as SSD and YOLO. I start with using a single shot object detector called RetinaNet that included focal loss because it has the right balance of accuracy and speed so I can iterate faster.
From the detected bounding boxes, I apply non-max suppression in order to reduce overlapping boxes of the same class.
For the bounding boxes of objects that have attributes (ex: chair is wooden), I use the object’s bounding box to feed into the attribute classifier, which takes in an image.
If objects overlap with other objects (chair overlaps with table), I take their combined bounding box as input for the 2-object relationship classifier. I exclude objects that don’t have known relationships (chair overlaps with horse).
After the relationship classifier returns the probability distribution across the 300+ relationship classes, I feed the result into a ranker that is trained to eliminate unlikely relationships. This ranker started very simple as the probability distribution of how likely the relationship existed in the dataset.
Dataset Challenges
Class Frequencies
One of the challenges is in this competition is the imbalance of how often certain objects/relationships exist.
Here are the top labels and their frequencies:
Table is Wooden 40682
Chair at Table 36289
Chair is Wooden 34609
Man at Table 28967
Chair is Plastic 20722
Woman at Table 19785
Bottle is Transparent 18077
Guitar is Wooden 12701
Chair is (made of)Leather 11259
And some of the bottom labels:
Boy holds Suitcase 1
Woman holds Fork 1
Boy inside_of Taxi 1
Man holds Briefcase 1
Boy holds Flute 1
Cat under Car 1
Cat inside_of Backpack 1
Girl holds Snowboard 1
Cat on Oven 1
Boy holds Knife 1
The network is going to have a hard time detecting any of the labels with only 1 sample. I deal with this somewhat by feeding the object labels and the confidence of the object detection network into the relationship classification network. For ex: if we’re confident that it’s a boy and it’s a flute, and there’s only one relationship that boy+flute can have, then it’s trivial to predict the relationship. In reality, objects can have many relationships with other objects.
Ways to deal with data frequency imbalance:
- Data augmentation using image transformations (flips might help here)
- Data augmentation using external data (existing Wikipedia or Google Image Searches)
Considering Class Hierarchies
Some classes are closely related to the other classes and others are subsets of other classes.
Similar classes:
- Man vs Boy
- Woman vs Girl
Subclasses:
- Cat is a child class of Animal
For these similar classes, I include similar classes and parent/child classes in the inputs of the relationship classifier.
Distinguishing between Attributes vs Relationships
Certain objects need to be identified for their attributes in addition to relationships. For example for wooden chairs, one of the goal is to predict chair is wooden as well as chair at table (if the chair is at a table).
From the data, there are 42 attribute triplets that I need to detect.
I use two image classification models:
- One takes in the cropped region of the image, the two types pf objects detected, and their relative bounding boxes-> relationship
- One takes in the cropped region of the images, the type of object detected-> attribute
Completeness of Ground Truth Labels
There are images in the dataset that don’t have all the relevant objects labeled.

For example, the large chair in the image above is not labeled, but all the smaller chairs are because they have relationships to other objects. If my network were to detect that the big chair had a relationship, then the score would be penalized.
Large size of Dataset
On the training set, there are millions of bounding box labels inside about 1 million images. Even a forward pass (prediction only) through an object detection network will take some time. So I test and iterate on a sample of the full dataset that has at least one image with each of the 329 relationships. This caused the frequency distribution of relationships to be off from the original dataset, but it allowed me to quickly rule out approaches that didn’t work before training on the full dataset.
To parallelize training, I could:
- Distribute the computational load over multiple GPUs and then aggregate the results in the CPU. When I tried this, I found that there was a CPU bottleneck to combine the results of the GPUs.
- Distribute the load over multiple machines, each with GPU and CPU. I did not try this (mainly out of cost concerns) but would try it in the future if I had the infrastructure.
Scoring
The evaluation metric for the competition is a weighted average of:
- How precisely can the model predict the bounding boxes for both objects and correctly identify the relationship between them. The boxes have to overlap with the ground truth labels at least 50% to be considered. Also known as mean-average precision (mAP) of the boxes and relationship. False positives are penalized.
- How many of the relationships the model can detect? (recall)conservative If the model is too conservative and only returns 99.9999% sure predictions, this metric will be penalized.
- How precise is the bounding box that envelops both objects’ bounding boxes, used to describe the relationship. In the first picture above, this is the red box.
From this scoring, it’s imperative to have a good object detector because both the precision metrics depend on having accurate bounding boxes.
Results
After training my object detector on a single pass of 10% of the data, I was able to get good results to validate my approach.
For example, here are outputs of the bounding box detector:
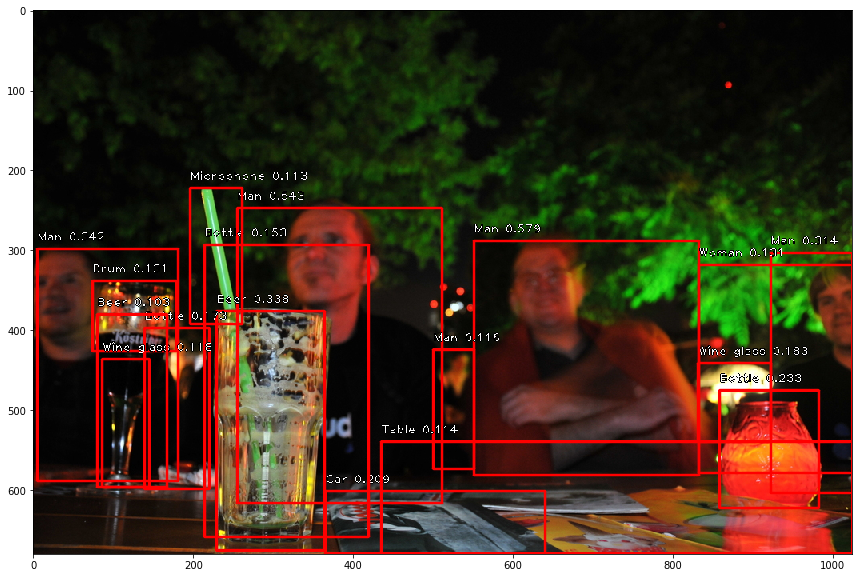
There is a lot of noise and some false positives, for example: it thinks the strong is a microphone.
There are overlapping also a lot of overlapping boxes that have the same label. To combine overlapping boxes that have the same label, I applied non-max suppression to combine similar boxes into one. This reduces the number of images that I need to feed into the relationship classifier.
From the bounding boxes, here are the only objects with possible attributes (ex: bottle is glass)

Despite making good progress in the early stages of the competition, I didn’t finish training my object detector and didn’t finish training the other relationship classifier.
Next Steps
Finish!
- Reduce number of classes / relationships and training samples to get to good enough result
- Implement techniques from top finishers
- Post code to GitHub
Other readings from top finishers of the Kaggle competition:
- 2nd place by tito
- Notable:
- Use of Light GBM for score prediction (what I call the ranker)
- 5th place by radek
- Notable:
- Using embeddings for relationship word and both label words
- 7th place by anokas
- Notable:
- Use of Google’s pretrained Faster R-CNN for object detection
- Use of Euclidean distance between the two box centers and Euclidean distance normalized by the size of the boxes (zoom invariance)
- Use of 5-fold XGBoost model (ref k-fold cross-validation and XGBoost)
- 8th place by ZFTurbo
- Notable:
- Great writeup with failed experiments