Goals
Supervised machine learning models are only as good as the data they were trained on. If the data contains cultural or geographical bias, the model will only amplify the existing bias. In the case of image classifiers, training data from one geographical region might not produce a model that works well when introduce to never-before-seen data from another region.
Google challenged Kagglers to create models that are more robust and delivers inclusive results in the diverse world we live in.
Here is the distribution of the sources for the train and test data sets:

Data Exploration
The competition uses training data from the massive Open Images dataset provided by Google.
In addition to the training data, Google also provides:
- A stage 1 test images set
- Tuning labels (Ground truth) for a subset of the stage 1 test image set
- Bounding boxes and object labels for the training set
- Human labels for the training set
- Machine labels (with confidence scores) for training set
Kagglers can also use the Wikipedia text corpus to improve how the model understands the association between two labels (ex: Human+Shopkeeper makes sense while Horse+Shopkeeper does not).
However the competition prohibits using the object hierarchy data from the Open Images data set and the neutral network cannot be pre-trained (using ImageNet for example).
The size of the training set is big:
1743042 images with 7000+ unique labels
8036466 Human-labeled labels on training images
15259186 machine-labeled labels on training images
14610229 bounding boxes on 1743042 training images
Many Kagglers did Exploratory Data Analysis (EDA) of the data.
I found the interactive graphs of jtlowery great. Here are some highlights:
How many unique labels are there per image?
(We only need to identify one label of each type per image)
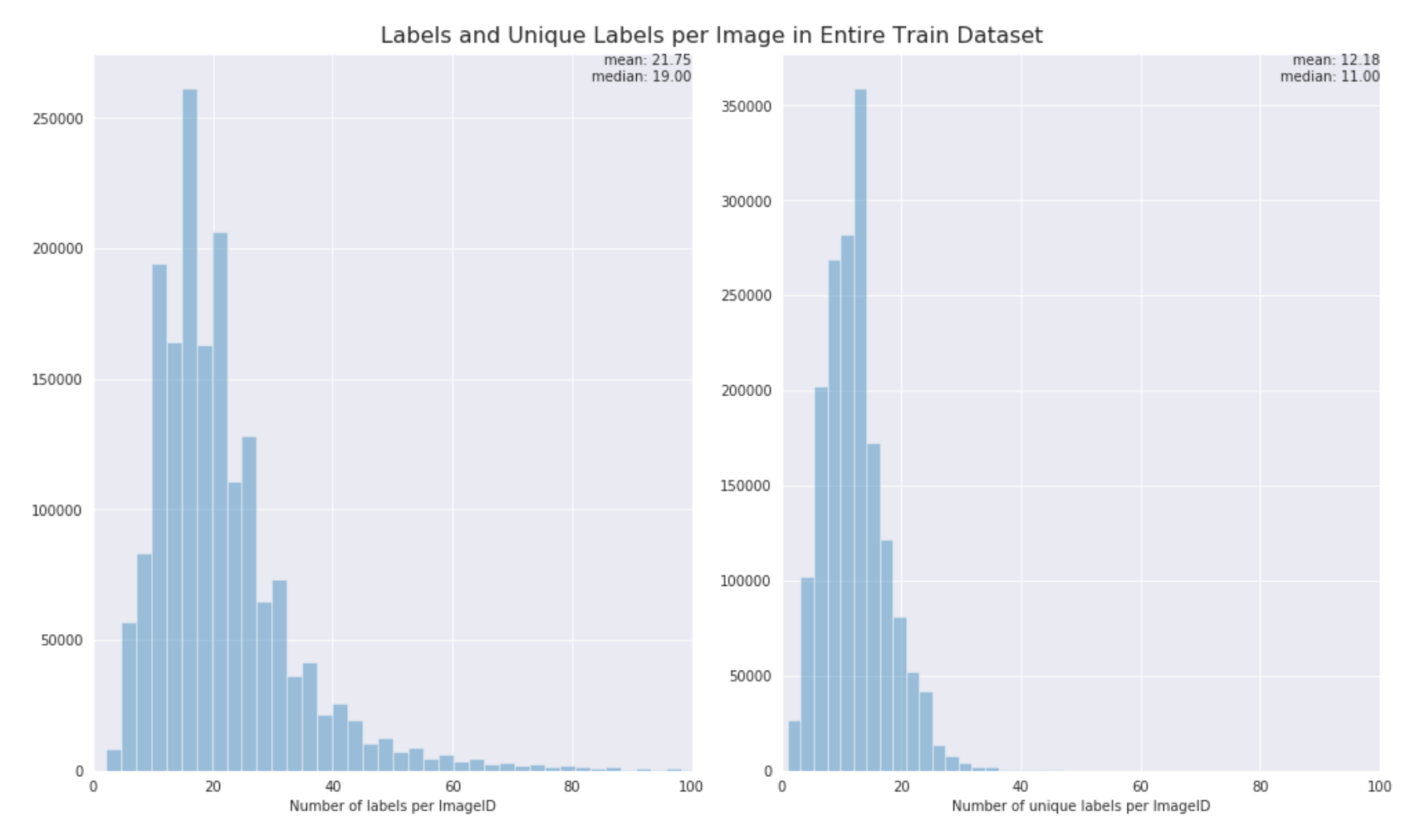
What are the most common labels?
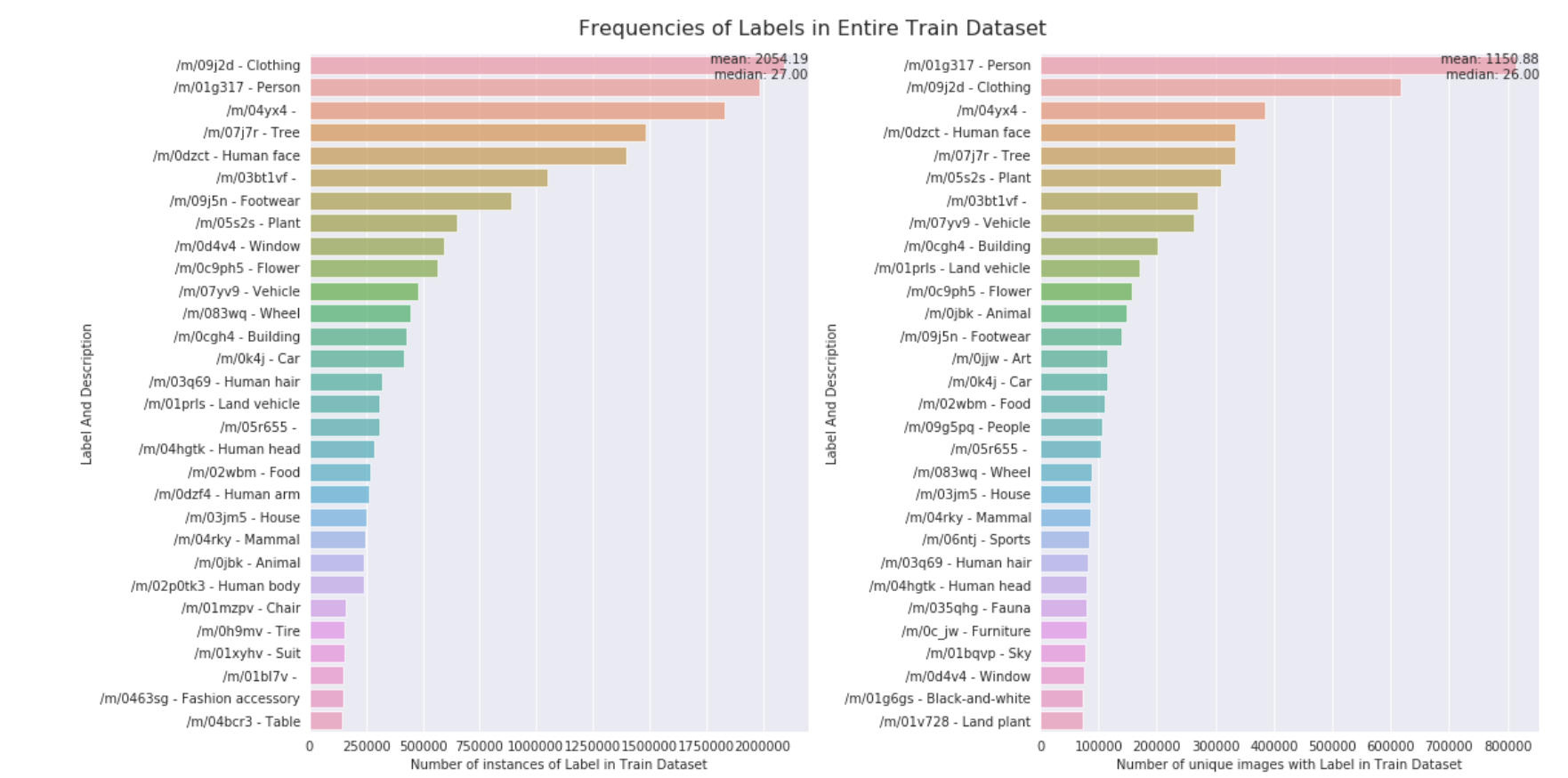
I recommend checking out the original kernel here to see the interactive charts.
Scoring
The competition is judge using an F2 metric, which favors recall over precision. In layman’s terms, the scoring rewards getting as many right answers as possible and doesn’t penalize wrong predictions as harshly.
Approach
With so many labels per image, the challenge is finding the most important labels per image. Unlike most image classification tasks, there are no “correct” labels to train the model. The dataset contains a mix of human labels, bounding boxes around the objects in the images, and machine generated labels. It’s up to me to figure out which labels are important. After the labels are figured out, I think any image classifier (ResNet50) would do a fine job of learning to associate labels to images.
My first approach is to use all the labels. This brute force method resulted in less iteration time on the neural network architecture and more time machine sure my cloud GPU doesn’t barf.
My second approach uses some data manipulation.
- Assign a confidence next to every labels (human, machine, bounding box)
- Human labels have confidence of 1.0, machine labels have confidence scores provided as part of the dataset
- For the bounding boxes, I use the bounding box area to create a pseudo confidence score.
- Sum up all the confidence scores for each unique label for the image.
- Filter out the labels with low confidence scores (median - 1 standard deviation). The thinking is that this eliminates labels that are too specific.
The image classifier I ended up using was DenseNet121 (my code here). I chose it for its efficiency in memory and computation resources while maintaining a relatively high accuracy compared to the de-facto king of image classifiers: ResNet50.
Results
My second approach of crudely filtering out labels with low confidence scores meant my model were able to pick up common labels but missed specific, important details.
Example:

Tuning label ground truth:
['Person', 'Shopkeeper', 'Grocery_store', 'Supermarket']
Predictions:
['Person', 'Clothing', 'Footwear']
The predictions are not wrong, per se, they were just too generic. To correct this, I went back and fed the complete set of image labels through a model that was already trained on the generic labels. I then applied transfer learning (freezing every model layer except the last) to train on the (few) tuning labels.
The resulting predictions for this image are:
['Person', 'Clothing', 'Grocery_store', 'Supermarket']
That’s more like it!
The competition scores submission in two stages. Each stage contains data from different regions in the world.
Across both stages of the competition, my F2 score for the test data was 0.19182, earning a 24th place and my first silver medal in a Kaggle competition.
Next Steps
After reading about others’ solutions, I’ll try:
- Training more models and combining into an ensemble (the size of the dataset scared me)
- Use both train time and test time data augmentation to make the model more robust (this could be as simple as applying horizontal flips to an image)
- Using random crops as a augmentation technique
- Using the Wikipedia text to enhance the model’s ability to reason about associations between object labels
- I didn’t see many solutions use this corpus
Other Solutions
- 1st place solution by Pavel Ostyakov
- Freeze a network and adapt only the last layer to perform better on these images
- The distribution on images doesn’t matter while distribution of targets does
- final solution contains ~300 models
- 2nd place solution by vecxoz
- Ensemble of ResNet50, InceptionV3, InceptionResNetV2
- Train and test time augmentation
- 4th place solution by Azat Davletshin
- Single model
- Used all 18k labels instead of 7k labels
- Custom MultiLabelSoftmaxWithCrossEntropyLoss function
- Crops for test-time augmentation